|
I am a PhD Student researching on video misinformation detection at the Ubiquitous Knowledge Processing (UKP) Lab under the supervision of Prof. Iryna Gurevych in TU Darmstadt, Germany. Previously, I worked at the Pacific Northwest National Laboratory (PNNL) located at Richland, Washington, USA, where I contributed to projects on domain-specific LLMs and NLP for environmental and scientific data. My broader interests lie at the intersection of Natural Language Processing and Vision-Language Modeling. I am passionate about building interpretable and transparent AI systems that help understand and mitigate misinformation in real-world multimodal settings. I am a graduate from the New Jersey Institute of Technology, with a M.Sc in Data Science with a thesis in Crisis Informatics under the guidance of Prof. Cody Buntain |

|
|
My research interests included, information extraction from unstructured data, and training and evaluation of Large Langauge Models on domain-specific data. |
|
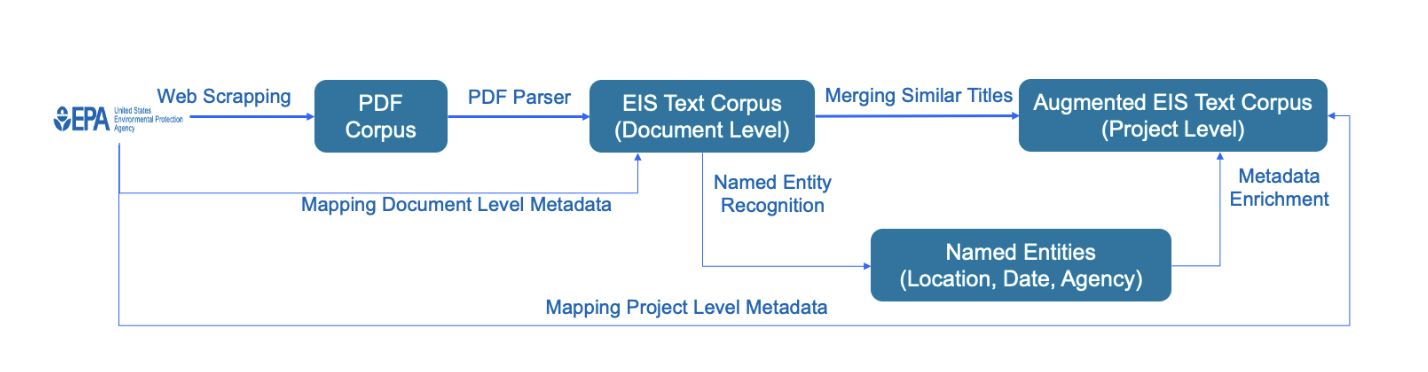
Shivam Sharma*, Dan Nally, Mike Parker, Sai Munikoti, Sameera Horawalavithana Paper Link / Dataset Link
|
|
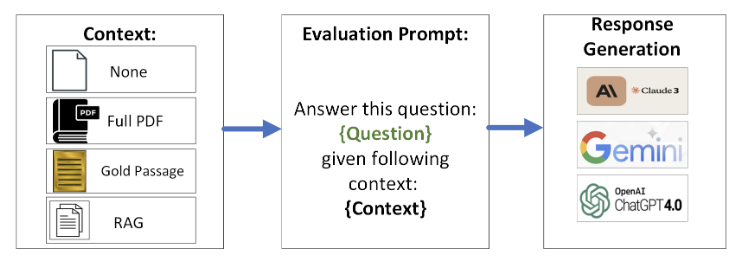
Hung Phan, Anurag Acharya, Sarthak Chaturvedi, Shivam Sharma*, Mike Parker, Dan Nally, Ali Jannesari, Karl Pazdernik, Mahantesh Halappanavar, Sai Munikoti, Sameera Horawalavithana Paper Link
|
|
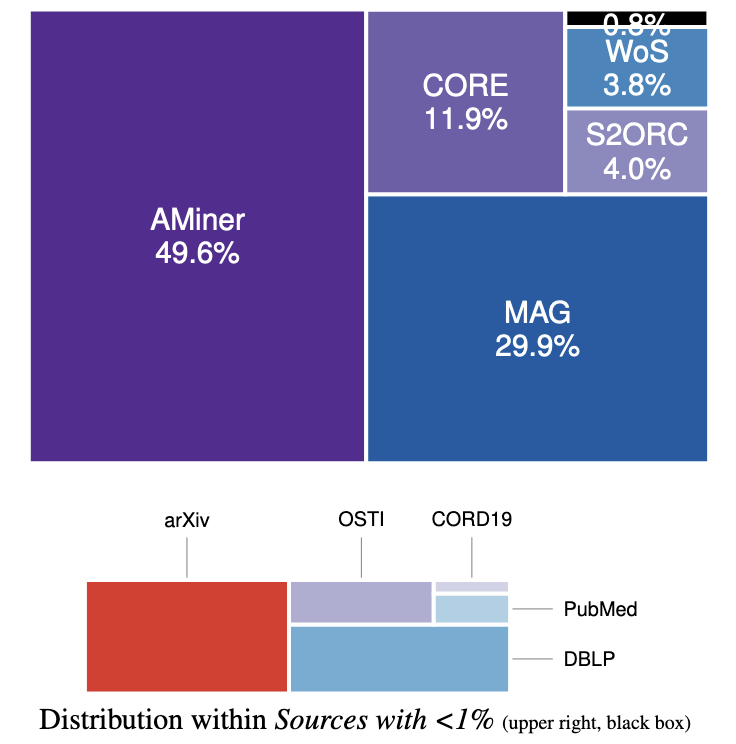
Sameera Horawalavithana, Ellyn Ayton, Shivam Sharma*, Sylvia Howland, Megha Subramanian, Scott Vasquez, Robin Cosbey, Maria Glenski, Svitlana Volkova, BigScience Workshop 2022 Paper Link
|
|
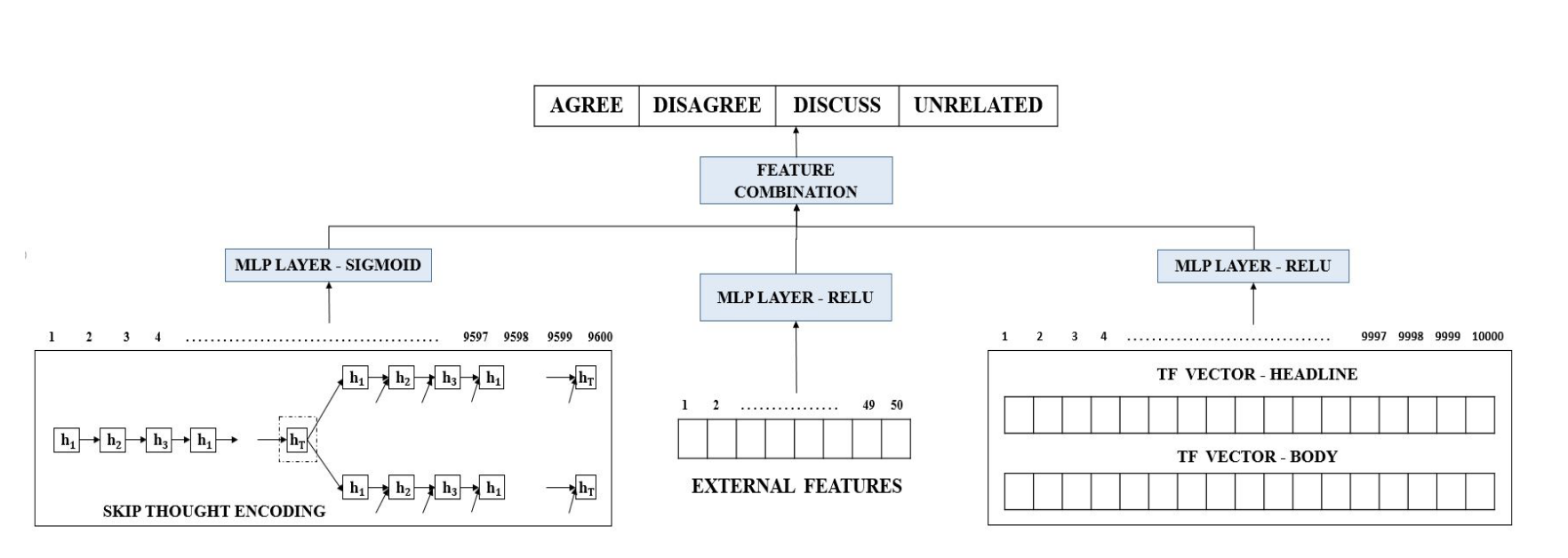
Gaurav Bhatt, Aman Sharma, Shivam Sharma*, Ankush Nagpal, Balasubramanian Raman, Ankush Mittal, MSM 2018 Paper Link / Github Code Link
|
|
|
|
|
Jan 2023 - Jan 2025
|
|
|
Oct 2021 - Jan 2023
|

|
Oct 2019 - Sep 2020 Supervisor: Dr. Cody Buntain
|

|
June 2017 - July 2017 Supervisor: Dr R Balasubramanian
|
|
I borrowed this website layout from here! |